Fractal Generative Models
Modularization is a cornerstone of computer science, abstracting complex functions into atomic building blocks. In this paper, we introduce a new level of modularization by abstracting generative models into atomic generative modules. Analogous to fractals
arxiv.org

한국 시간으로 25일에 최초로 나온 따끈따끈한 논문을 들고 왔다. 웬만하면 이런 짧은 제목의 논문은 잘 보지 않는 편인데, MASK R-CNN, ResNet, Focal Loss, FPN 등의 화려한 논문 기록을 가진 Kaiming He의 논문이었기에 집어들 생각이라도 한 것 같다. 논문의 제목으 Fractal Generative Model이다. 이후 FGM으로 줄여 부르도록 하겠다.
Abstract
Modularization is a cornerstone of computer science, abstracting complex functions into atomic building blocks. In this paper, we introduce a new level of modularization by abstracting generative models into atomic generative modules. Analogous to fractals in mathematics, our method constructs a new type of generative model by recursively invoking atomic generative modules, resulting in self-similar fractal architectures that we call fractal generative models. As a running example, we instantiate our fractal framework using autoregressive models as the atomic generative modules and examine it on the challenging task of pixelby-pixel image generation, demonstrating strong performance in both likelihood estimation and generation quality. We hope this work could open a new paradigm in generative modeling and provide a fertile ground for future research. Code is available at https://github.com/LTH14/fractalgen
굵은 글씨 쳐놓은 부분만 보면 어느 정도 이 논문에서 하고 싶은 말이 보이게 된다. 결국 모델에서의 Modulization의 범위가 Transformer 등의 기존 모델에서는 하나의 블럭이었다면, 이제는 모델 자체를 모듈화시켜서 하나의 모듈로 활용하겠다는 말인 것이다. 이게 어떤 말인지 지금 당장은 이해가 힘드니, 일단 다음으로 넘어가보자.
Introduction
해당 부분에서는 앞의 Abstract와 같이 주로 모듈화의 향상을 핵심 아이디어로 가져간다. 기존 모델들이 layer 관점에서 모듈화를 진행하였다면(앞에서 '블럭 단위'라고 설명), 해당 모델 구조에서는 모델 자체에 대한 모듈화를 진행하여 이에 대한 프랙탈 아이디얼르 생성 모델에 접목하여, 자기 유사성(self-similarity)를 갖는 새로운 형태의 Generative Model을 제안한다. 이로써 얻고자 하는 목표는 주로 '픽셀 단위의 직접 이미지 생성' 문제이다. 여기서 기존 방식들이 AutoRegressive Model(이하 AR), Masked AutoRegressive Model(이하 MAR) 등의 모델에서는 우도 추정의 정확함을 보장하지만 시각적 품질이 떨어지고(픽셀 단위로 추론하기 때문), 이후 나온 Two-Stage Generator나 토큰화 등의 모델들(VQ-VAE + AR, MegaByte 등)을 통해 시각적 품질을 향상시켰지만 아직 성능 상의 문제가 남아 있고, 우도 추정과 성능 향상 두 가지 토끼를 모두 잡지 못한다는 한계점이 존재하였다. 본 논문을 통해 주장하고 싶은 것은 픽셀 단위 이미지 생성 문제에서 우도 추정의 정확도, 그리고 생성된 이미지의 품질을 FGM을 통해 동시에 향상시킬 수 있다는 것이다.
Related Works
FGM 논문의 착아점은 생성 모델 자체를 모듈로 삼아 더 복잡한 생성 모델을 구현하자는 것인데, 이는 과거 나와 있던 FractalNet과 어느 정도 맥이 닿아 있다고 볼 수 있다.

FractalNet은 다음과 같이 Convolution Block에 대한 재귀적 호출을 이용해서 깊은 신경망을 만든다는 특징이 존재한다. 비슷한 구조이지만, FractalNet이 분류용 신경망에 국한되고 재귀적으로 확장되는 것이 Convolution 블록 하나라는 한계점이 존재하는 반면 FGM은 전체 생성 모델을 모듈로 삼아 High-Dimensional Output을 뽑아내는 것이 목표임이 다르다고 할 수 있다.
기존 모델들과 비교
- GAN : 생성형 모델이라고 하면 가장 먼저 생각나는 모델일 것이다. 이는 생성자에 판별자를 두어서 학습하며 직접 픽셀들의 분포에 대한 학습을 수행하기 보다는 말 그대로 생성 - 판별 사이의 균형을 통해 학습하는 방식이지만, FGM은 우도 기반의 직접 학습을 통해 명시적인 확률 추정이 가능하게 된다. 그렇기 때문에 FGM은 픽셀 단위의 우도 추정이 가능하도록 되고, 실제 실험에서도 더 우수한 성능을 보였다고 한다. 하지만 FID 등의 샘플 다양성의 측면에서는 어쩔 수 없이 GAN보다 살짝 열세일 수 밖에 없다고 한다. Noise같은 구조가 추가로 들어가는 것이 아닌 단순 재귀적인 AR / MAR을 통해 비교했기 때문이 아닐까 생각해본다.
- VAE(or VQ-VAE) : 모르면 일단 여기 를 보고 오시길 바란다. 설명 잘 해놓으신 것 같아서 적어본다. 보고 오시면 알겠지만, VAE나 VQ-VAE 등의 모델은 latent space를 추출하고, 거기에서 샘플을 뽑아 이미지를 복원하므로 어느 정도의 손실이 발생할 수 있다. 하지만 FGM은 원본 Pixel Space에서 직접 학습 / 생성을 수행하기 때문에 복원 오류가 없다고 한다. << 이게 좀 걸리기는 하는데 일단 나중에 좀더 코드 까보고 다시 와야겠다.
- Diffusion : 디퓨전 모델은 여러 단계에 걸친 생성을 진행함과 반대로, FGM은 한 번의 재귀 FF로 이미지 생성을 완성하기 때문에 디퓨전 구조보다 훨씬 직관적인 구조가 되게 된다. 또한 FGM은 Divide-and-Conquer 구조를 사용하기 때문에 직접 고해상도 픽셀 생성을 달성하였다. 그래서 더 직관적이며, 우도 추정에서도 Diffusion 모델들과 비슷한 성능을 내는 것을 확인할 수 있었다.
- AutoRegressive(AR) : 이 구조는 FGM에서 하나의 모듈로 사용하느 모델 구조이다. 기존 AR 모델들은 Pixel 수가 많아지면 계산량이 너무 많아지는 문제가 존재하고, 이미지의 Spatial 구조를 활용하지 못한다는 것에 제약이 있었는데, 이를 재귀적으로 사용하고 계층적으로 사용함으로써 효율적으로 고차원의 공동 분포를 추정하게 된다. 이는 계산량이 크게 감소하고, NLL 또한 크게 감소시키며 큰 향상을 가져올 수 있도록 하였다.
Method
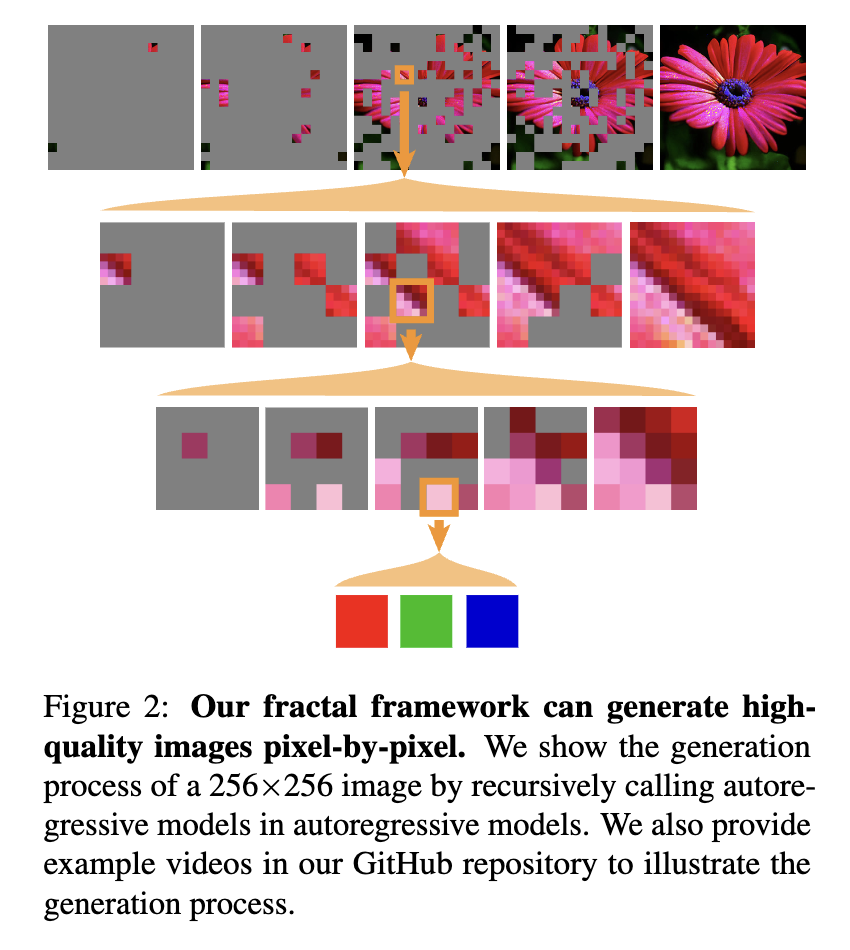
같은 말을 몇 번씩 하게 되는 건지는 모르겠지만, FGM의 핵심 개념은 기존의 생성 모델을 원자 생성자 모듈로 모듈화하고, 이를 재귀적으로 호출하여 상위 모델을 구현하는 방식이다. 위의 이미지를 보면, 전체 High-Resolution Image에서 한 patch 내에서 다시금 ar 모델이 호출되고, 그 내에서 다시 ar 모델이 호출되는 식으로 같은 패턴이 여러 계층에 걸쳐서 반복되는 것을 확인할 수 있다. 이는 실제 프랙탈 구조에서 생성 규칙이 반복적으로 적용되는 것과 같다. 이렇게 반복적으로 적용되게 되면 출력 차원은 기하급수적으로 증가하지만 필요한 재귀 단계의 수는 선형적으로 증가한다는 이점이 발생하게 된다. 이러한 이점을 통해, FGM은 상대적으로 적은 레이어를 거치면서도 거대한 출력 공간을 만들어낼 수 있게 되며, 이를 통해 성능 향상을 꾀한다는 것이 본 논문의 목표이다. 이러한 구조는 결국 어느 정도는 예상했다시피 계층적으로 Divide-and-Conquer 방식을 거치며 진행되게 된다. 본 논문에서는 단방향 AR, 양방향 MAR 2가지를 각각 FractalAR, FractalMAR로 사용하니, 이를 추후 참고하길 바란다.
학습과정
FGM의 학습은 end-to-end로 진행된다. 학습 당시에는 전체 Architecture를 BFS로 거치며 각 레벨의 모든 출력을 생성한 후, 마지막 픽셀 레벨에서 계산된 Cross-Entropy Loss를 다시 역전파하여 모든 레벨의 파라미터를 한번에 업데이트시킨다. 하나의 loss로 전체 재귀 모델들을 한 번에 최적화하는 것이기 때문에, 통합적으로 최적화가 이루어진다.
생성과정
이 때에는 DFS 방식으로 재귀를 진행한다. 패치 단위로 레벨 1 AR 모듈부터 시작하여 토큰을 생성하되, 패치 내에서 다시 패치를 나누어 레벨 2 AR 모듈로 생성을 진행하며 차근차근 내려가는 방식이다. 이와 같이 픽셀 단위 생성을 진행하기 때문에, 사람이 보기에도 추적이 가능하고 해석 또한 가능하다는 장점이 존재한다.
Experiments
본 논문에서는 ImageNet dataset을 64x64, 256x256 2개로 나누어 생성을 진행하였다. 64x64 이미지를사용한 것은 unconditional generation을 통한 NLL 평가에 사용하기 위함이고, 256x256 이미지의 생성은 class-conditional generation을 통한 생성 이미지 품질 평가를 위해 사용했다고 생각하면 된다. FGM의 재귀 레벨은 64x64 모델의 경우에는 3단계(패치 - 픽셀 - RGB 회귀), 256x256 모델의 경우에는 4단계(패치 - 패치 - 픽셀 - RGB 회귀)로 구성되었다.
NLL(Log-Likelihood)

이미 어느 정도 예상했다시피 충분히 좋은 성능이 나오게 되었다. 하나의 AR 모델로 64x64 이미지에 대해서 모두 시퀀싱하는게 굉장히 복잡하다는 건 어느 정도 예상할 수 있었겠지만, FGM의 경우에는 이걸 패치 단위로 재귀적 수행을 진행하기 때문에 AR모델을 사용한 기존의 방식은 물론 diffusion을 사용한 방식보다도 로그우도가 오히려 더 좋은 결과를 보였다. 로그 우도를 여기서 주로 이야기하였지만, 여기서 뭔가 더 효과가 좋다고 생각이 되었던 부분은 연산량이라고 할 수 있을 것 같다. AR 구조를 이용해서 오히려 더 좋은 성능을 낼 수 있으면서도 더 값싼 연산이라... 논문 다 보고 나서 코드를 한 번 까보면서 제대로 실행을 해봐야겠다.
Generation Quality
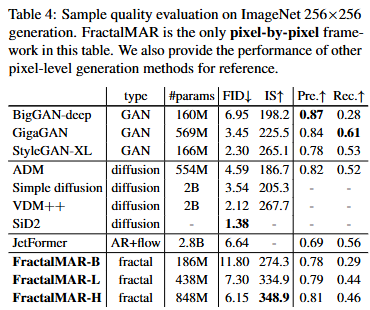
이건 이제 256x256 generation을 기준으로 진행하였다. FID는 아무래도 Diffusion / GAN과 같은 모델들에 대해서 낮게 나타났지만, 이는 이제 AR을 기반으로 한 픽셀 기반 생성 프레임워크를 기준으로 생각했을 때 확실히 높은 성능이라고 볼 수 있다. Latent Space에 대한 Matching이나, Diffusion구조에서의 Noise와 같은 다양성이 존재하지 않아. FID는 잘 나올 수 없는 구조인 것 같다. 그래서 조금 더 눈여겨봐야 할 내용은 IS(Inception Score), Precision 2가지 내용이 될 것 같다. 확실히 픽셀 단위의 직접 생성 모델이기 때문에 Latent Space에서의 복원 오차가 존재하지 않고, 그렇다는 것은 파라미터 수가 늘어날수록 선형은 아니겠지만 성능의 향상이 기대된다는 것이기 때문이다. 현재 단순 AR 모델로 생성을 했음에도 이러한 성능을 냈는데, 여기에 추가적인 연구가 진행되면 어떨지 기대가 되는 대목이다. 이미 가벼운 모델들도 Inception Score는 다 발라버렸기 때문에...
Discussion
FGM에서 가장 큰 내용은 더 이상 이미지의 픽셀 수와 연산량이 선형적이지 않게 변할 수 있다는 것 같다. 또한 픽셀 단위 이미지 생성의 연산량 문제를 해결하는 방식이 기존의 단순한 압축이나 Quantization이 아니라, 데이터 자체의 계층적 구조를 반영한 재귀적 설계라는 점이 재밌던 것 같다. 기존 AR 모델이나 확산 모델은 해상도가 커질수록 연산량이 기하급수적으로 증가하는데, FGM은 프랙탈 모듈의 재사용을 통해 연산량 증가를 완화할 수 있다. 이를 통해 고해상도 생성의 연산량이 확실히 감소한다는 것이 흥미롭다. 256x256 이미지의 AR 기반 생성이 64x64 이미지의 생성의 2배 연산량밖에 되지 않는다는 것이 말이 안된다.
다만, 샘플링 속도가 GAN 대비 여전히 느리다는 점, FID가 최상위 모델들보다 다소 높게 나온 점 등은 단점으로 지적될 수 있다. 또한 프랙탈 구조가 모든 유형의 데이터에 효과적인지, 아니면 이미지처럼 자기유사성이 강한 데이터에 한정된 방법론인지는 추가 연구가 필요할 것이다. 하지만 FGM이 보여준 성능과 확장 가능성을 고려하면, 앞으로 텍스트, 3D 데이터, 비디오 등 다양한 도메인에 적용될 가능성이 크다. 특히 고해상도에서 픽셀 단위로 정밀한 디테일을 유지하면서도 연산량을 줄일 수 있는 접근법이라는 점에서, 향후 생성 모델 연구의 중요한 흐름이 되지 않을까 싶다. 열심히 공부하고 더 발전해봐야겠다. 코드부터 까보러 가야지... 다음 글은 아마 FGM 코드 까보는 글이 아닐까 싶다.
'Paper Review > Generative Model' 카테고리의 다른 글
| [논문리뷰] DDT : Decoupled Diffusion Trasnformer (0) | 2025.04.17 |
|---|---|
| [Paper Review] StyleGAN : A Style-Based Generator Architecture for Generative Adversarial Networks (0) | 2025.02.25 |

