A Style-Based Generator Architecture for Generative Adversarial Networks
We propose an alternative generator architecture for generative adversarial networks, borrowing from style transfer literature. The new architecture leads to an automatically learned, unsupervised separation of high-level attributes (e.g., pose and identit
arxiv.org
* 이 논문 리뷰는 StyleGAN 시리즈 논문에 대한 세미나를 준비하면서 작성된 글이기에, 다소 얕고 주인장의 주관이 담겼으며 세미나스러운 표현이 포함됨을 알고 읽어주시면 감사하겠습니다.
StyleGAN은 2019년 CVPR(Computer Vision and Pattern Recognition)에 소개된 NVIDIA 연구소의 논문으로써, 추후 이를 기반으로 한 Style Transfer model들과 이후의 모델 발달에 큰 영향을 기친 중요한 논문이다. 이는 직전 논문이었던 PG(Pro)GAN의 아키텍처에서 조금 더 Generator에 초점을 둔 연구로, 기존의 연구들이 Discriminator에 주로 치중하고 있던 것에 반대된다고 볼 수 있을 것이다.
Previous Works

StyleGAN이 나오기 전의 GAN의 발전 과정이다. Progressive Growing을 사용한 이전의 연구에서 이미지의 다양한 스케일에서의 '스타일'에 대한 수정을 어느 정도는 가능하게 하였으나, 특정 스타일의 삭제 정도만 가능한 특징이 존재하였다. 하지만 본 연구에서는 style-transfer에서 주로 이용되던 Adaptive Instace Normalization(추후 AdaIN으로 줄여 부를 예정)을 GAN에 도입함으로써, 결국 생성되는 이미지들 또한 다양한 스타일들의 조합이라는 생각 하에 다양한 스타일을 반영해서 스타일들의 조합으로 새로운 이미지를 Generate할 수 있게 된 것이다.
Model Architecture

모델 구조를 한번 살펴보자. 슬라이드에 나오는 그림은 Generator 구조로, 기존의 Generator과의 차이점을 살펴보자면
- Maaping Network를 통한 Latent Space에 대한 Mapping
- 이를 통한 Style Vector의 추가, 그리고 Noise Vector(=>Stochastic Variation)의 추가
- AdaIN 도입
- Synthesis Network의 Input을 4x4x512로 고정하였음.
의 차이점을 통해 기존과의 차이를 만들어내려 하였고, Generator의 구조를 다음과 같이 가지는 전체 모델의 구조는 아래와 같다.
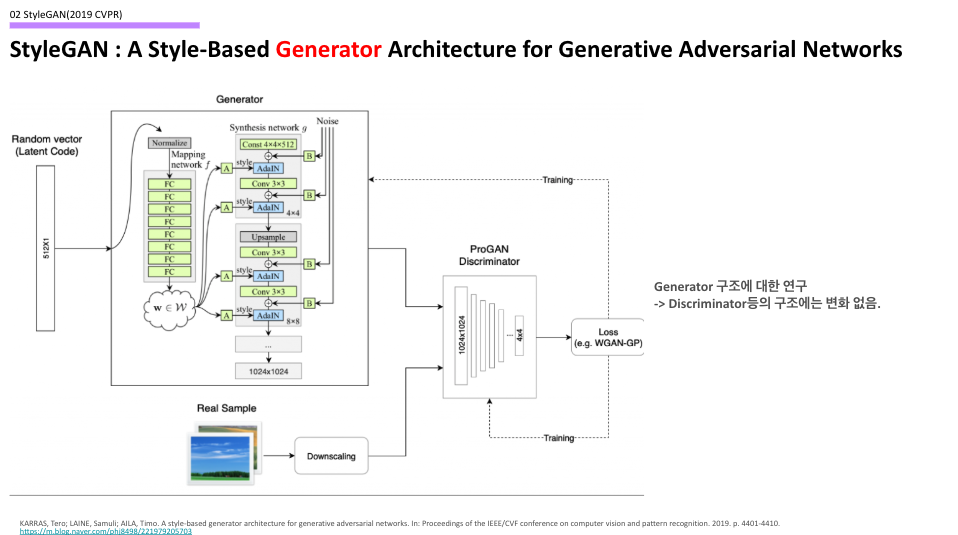
이는 앞의 GAN 모델의 발달 순서에서 보았듯, ProGAN 이후의 후속 모델로 나온 모델이기 때문에 ProGAN(==PGGAN)의 Discriminator 구조와 Wassertein Distance를 Loss로 사용하는 학습 구조를 가지고 있다. 만약 이 GAN이라는 모델의 전반적 구조가 이해가지 않는다면, 지금이라도 그 구조를 다시 보고 오는 것을 추천한다. 지금부터는 Generator 구조를 하나하나 뜯어보자.
Mapping Network
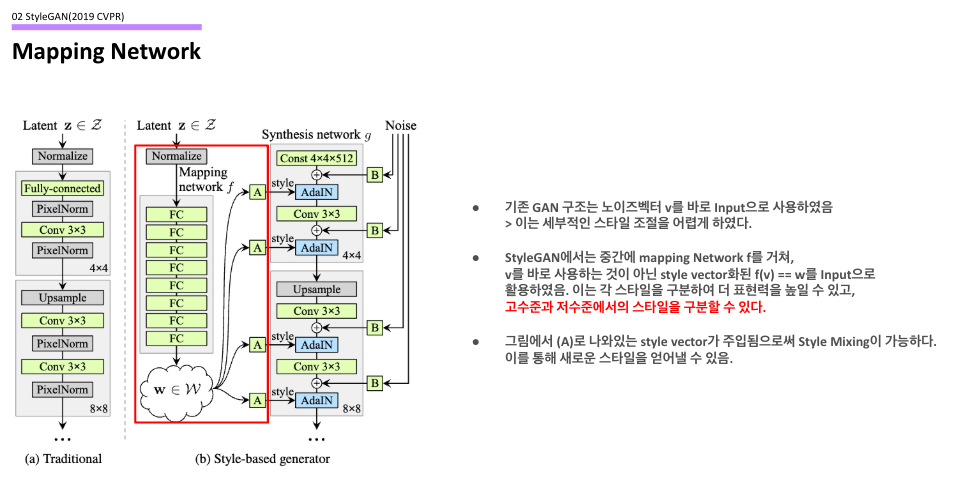
슬라이드에 나와있듯, 기존 GAN 구조는 노이즈벡터 v에 대해 이를 바로 input으로 사용하였기 때문에, 이러한 균일한 분포를 가지는 input은 세부적인 스타일 조절을 어렵게 만들었다. 하지만 StyleGAN은 중간에 FC Layer를 쌓아놓은 Mapping Network를 거치면서 비선형적 변환을 수행하였고, 각 스타일들에 대한 구분력을 높이고 조금 더 표현력 높은 특징들을 가지도록 한다. 또한, 이를 통해서 본 논문에서 가장 강하게 주장하는 'Style Mixing'이 가능하도록 된다. 이를 저자는 Latent Space에 대해서 Disentanglement를 수행한다고 한다. 결국 vector 사이의 seperability를 추구한다는 것이다.
GitHub - NVlabs/stylegan: StyleGAN - Official TensorFlow Implementation
StyleGAN - Official TensorFlow Implementation. Contribute to NVlabs/stylegan development by creating an account on GitHub.
github.com
향후 모든 코드는 여기를 참조하기를 바란다. tensorflow implementation이라는 것이 아쉽지만, 뭐 어쩌겠나 봐야지...
AdaIN(Adaptive Instance Normalization)
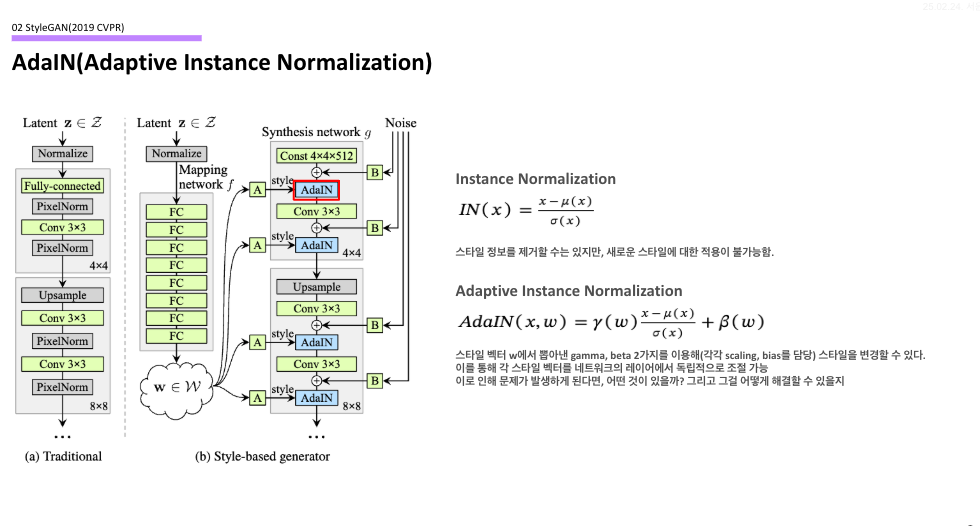
다음은 AdaIN이다. 이 또한 Instance Normalization의 일종인데, 기존 방식과 다른 점이라고 한다면 w라는 input의 gamma, beta 값을 이용한다는 것이다. 여기서 gamma, beta는 각각 scaling과 bias를 담당하는 파라미터로, 들어오는 스타일 벡터(그림에서는 A)의 값을 이용하여 스타일들에 대한 혼합을 가능토록 한다.
하지만 이 방법에도 문제가 존재하게 되는데, 바로 style vector가 계속해서 입력되는 과정 속에서 과도하게 편향된 input이 들어오게 될 경우에는 과도하게 정규화가 일어날 수 있다. 이러한 문제를 해결하기 위해서 저자들은 일종의 trick을 제안하게 되는데, 이것이 바로 Truncation Trick이다. 이는 style vector를 생성할 때, 생성된 latent vector를 전체 latent space의 무게 중심으로 보간하여 과도한 정규화를 방지하는 역할을 하고, 이를 통해 문제를 어느 정도 해결하였다.
Stochastic Variation
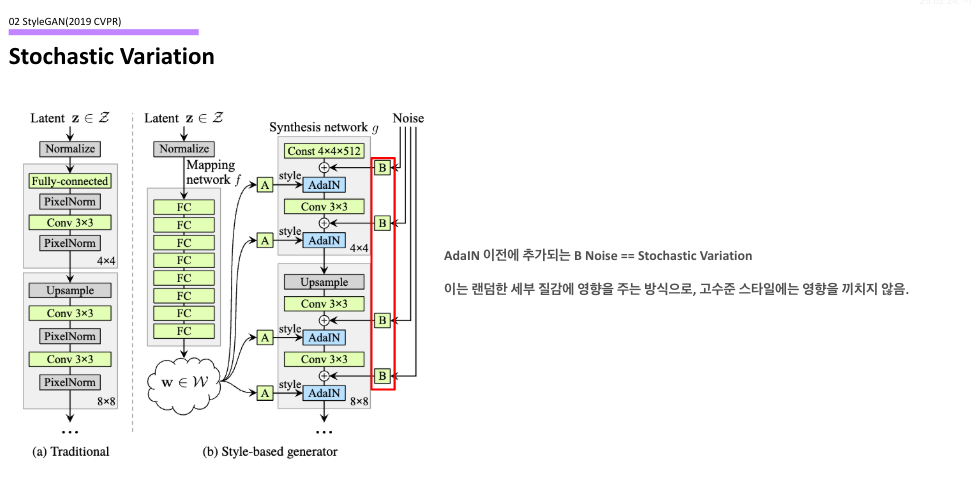
오른쪽을 보면, convolution 연산이 완료된 이후에 계속해서 random noise를 추가하는 것을 볼 수 있다. 이는 AdaIN 연산 이전에 추가되기 때문에 스타일이 적용되기 이전에 적용되는 작은 noise라고 생각하면 되는데, 이는 랜덤한 세부 질감에 영향을 주는 방식이기 떄문에 고수준의 스타일(머리 스타일, 눈의 모양 등)에는 영향을 주지 않고 작은 특징(주름, 피부의 형태)에만 영향을 주게 된다.

논문에서의 실험 결과인데, 실제로 눈썹의 형태나 머리의 조금의 모양 등 작은 것에만 영향을 주고 큰 스타일에는 영향을 끼치지 않는 것을 볼 수 있다.
이와 같이
- Mapping Network의 도입
- AdaIN의 도입
- Stochastic Variation
- Style Mixing(Using Mapping Network) 사용
등의 방식을 이용하여, GAN 이미지 생성에서의 하나의 큰 획을 그은 논문이라고 생각이 든다. 하지만 이 구조에서도 문제가 발생하였고 이에 대한 해결책으로는 이후 가져올 StyleGAN 2 논문에서 알아보도록 하자.
'Paper Review > Generative Model' 카테고리의 다른 글
| [논문리뷰] DDT : Decoupled Diffusion Trasnformer (0) | 2025.04.17 |
|---|---|
| [논문리뷰] Fractal Generative Models (0) | 2025.02.26 |

