
이번에 리뷰를 작성할 논문은 지난달 말에 나온 Photo Recrafting 논문인 InfiniteYou이다.
InfiniteYou: Flexible Photo Recrafting While Preserving Your Identity
Achieving flexible and high-fidelity identity-preserved image generation remains formidable, particularly with advanced Diffusion Transformers (DiTs) like FLUX. We introduce InfiniteYou (InfU), one of the earliest robust frameworks leveraging DiTs for this
arxiv.org
Abstract
Achieving flexible and high-fidelity identity-preserved image generation remains formidable, particularly with advanced Diffusion Transformers (DiTs) like FLUX. We introduce InfiniteYou (InfU), one of the earliest robust frameworks leveraging DiTs for this task. InfU addresses significant issues of existing methods, such as insufficient identity similarity, poor text-image alignment, and low generation quality and aesthetics. Central to InfU is InfuseNet, a component that injects identity features into the DiT base model via residual connections, enhancing identity similarity while maintaining generation capabilities. A multi-stage training strategy, including pretraining and supervised fine-tuning (SFT) with synthetic single-person-multiple-sample (SPMS) data, further improves text-image alignment, ameliorates image quality, and alleviates face copy-pasting. Extensive experiments demonstrate that InfU achieves stateof- the-art performance, surpassing existing baselines. In addition, the plug-and-play design of InfU ensures compatibility with various existing methods, offering a valuable contribution to the broader community.
Abstract를 보고 정리하자면 이 논문의 main contribution은
- InfuseNet을 사용하여 feature를 residual connect를 통해 주입함.
- single-person-multiple-sample 데이터를 이용한 pretraining과 SFT를 포함한 Multi-Stage Training을 통해 Alignment 유지
의 2가지라고 생각하면 될 것 같다. 이제 간단히 이를 유념한 상태로 논문을 읽기 시작하면 될 것 같다.
Introduction
Introduction에서도 대부분 같은 얘기를 하지만, 더욱 심화된 이야기를 한다고 생각하면 된다.
기존 모델들의 문제점
1. Identity Similarity가 떨어진다.
2. Text-Image ALignment가 제대로 이루어지지 않거나, editability가 떨어진다. 그리고 상황에 맞지 않게끔 얼굴이 복사-붙여넣기 되는 경우가 많음.
3. flux 자체의 generation capability가 떨어지기 때문에, 결과물이 제대로 나오지 않게 됨.
이러한 문제점들을 해결하기 위해 위에서 언급한 Main contribution을 적용하였다고 한다. 이제 Methodology 파트로 넘어가, 본 논문에서 주장하는 구조에 대해서 알아보도록 하자.
Methodology
Preliminary
- ODE
기존 SDE방식(편미분)방식은 확률론적이고, 계산이 복잡해 속도 또한 느려서 결정론적이지 못하다는 단점이 존재하였다. 이 문제를 해결하기 위해 probability field가 아닌, 직선적인 Vector Field를 Regression하는 SDE(상미분방정식)을 통한 직선 근사를 사용한다고 생각할 수 있을 것이다. - Text-to-Image DiT
본 논문은 기본적으로 Stable Diffusion, FLUX의 구조를 차용한다. 또한, Text Encoder로는 T5-XXL과 CLIP을 사용한다고 생각할 수 있을 것이다.
Architecture

주로 이와 같은 Photo Recrafting 기법들은 IP-Adapter 기반의 구조를 사용하는 경우가 많다. 하지만 figure의 (b)를 보게 되면, text-image alignment가 ip adapter를 통해서 해쳐지는 경우가 존재한다. 그렇기 때문에 본 논문에서는 이와 같은 구조를 사용하지 않았고, DiT에 ControlNet의 일종인 InfuseNet을 사용하여 이미지 생성을 수행하였다.

본 아키텍처를 보면, 정말 학습시키는 것은 InfuseNet밖에 없다고 생각하면 될 것이다. DiT는 InfuseNet에서 넘어오는 block과 Noise Map, 그리고 텍스트 인코딩만을 받아서 이미지의 생성을 진행한다.
여기서 InfuseNet에 대해 조금 더 설명해야 InfiniuteYou의 구조에 대한 이해가 가능할 것이라고 생각해서, 이에 대한 설명을 더 하고 지나가보자.
InfuseNet
InfuseNet은 DiT(Diffusion Transformer) 기반의 베이스 모델에 인물 아이덴티티 정보를 효과적으로 주입하기 위해 고안된 컴포넌트이다. 이 모듈은 얼굴 이미지로부터 추출한 identity features를 projection network를 통해 변환하고, residual connections 방식으로 베이스 모델의 각 Transformer 블록에 더해준다. 그 결과 텍스트 기반 조건(text prompt)과 병행하면서도 높은 수준의 아이덴티티 유사성을 유지할 수 있다. InfuseNet을 적용한 생성 모델은 원본 인물의 고유 특징을 보존하면서 스타일이나 배경을 자유롭게 편집할 수 있다.
InfuseNet의 주된 목표는 identity preservation과 generation capability 사이의 균형을 맞추는 것이다.
- Identity Preservation: 얼굴 임베딩(face embedding)에서 추출된 identity features를 residual connection을 통해 주입함으로써, 생성된 이미지에서 인물의 주요 얼굴 특징을 놓치지 않는다.
- Minimal Impact on Generation: attention 레이어를 직접 변경하지 않고 residual connections만 활용해, 베이스 DiT 모델의 원래 생성 능력을 최대한 보존한다. 이 설계를 통해 IP-Adapter처럼 attention 모듈을 건드려 발생하는 text-image alignment에 대한 악화나 이미지 품질 저하 같은 부작용을 피하면서도 identity 유사성을 크게 향상시킨다.
InfuseNet은 베이스 DiT 모델(본 논문에서는 FLUX)의 구조를 따르되, 효율성을 위해 Transformer 블록 수를 줄여 설계한다.
- 블록 수 및 배치: 베이스 모델에 총 M개의 Transformer 블록이 있을 때, InfuseNet은 N=M/k개의 블록으로 구성된다. 각 InfuseNet 블록은 대응하는 베이스 모델 블록의 residual 출력을 예측하도록 학습된다.
- 프로젝션 네트워크: frozen face identity encoder를 통해 얻은 고차원 얼굴 임베딩을, 낮은 차원으로 재투영하기 위해 projection network를 사용한다. 이를 통해 차원이 일치된 identity features를 InfuseNet에 입력할 수 있다.
- 컨트롤 이미지: 필요 시 5-point facial keypoints 같은 컨트롤 이미지를 추가 입력으로 받아 인물의 위치나 구도를 제어할 수 있다. 사용하지 않을 때는 단순히 검은색 이미지를 입력해도 무방하다.
InfuseNet은아래와 같이 작동하게 된다.
- Identity Encoding: 입력된 얼굴 사진을 frozen face identity encoder에 통과시켜 고차원 identity 임베딩을 얻는다.
- Projection: 이 임베딩을 projection network로 전달해, InfuseNet이 사용할 수 있는 저차원 feature로 재구성한다.
- Residual Injection: InfuseNet의 각 Transformer 블록은 베이스 모델의 대응 블록에서 나오는 출력과 텍스트 임베딩 처리가 일어나는 중간 지점에 예측된 residual을 주입한다.
- 분리된 경로: 텍스트 조건은 attention 레이어로, identity 조건은 residual connections로 각각 처리되어 서로 간섭 없이 동시 반영된다. 이 과정을 통해 텍스트-이미지 정렬(text–image alignment)을 유지하면서 인물 재현력을 극대화한다.
기존 IP-Adapter과 같은 방식과의 차이점은 아래와 같다.
- Attention 레이어 비변경: IP-Adapter나 다른 adapter 방식은 attention 모듈에 직접 intervention을 가해 생성력을 저해하는 반면, InfuseNet은 residual connections만 사용해 부작용을 최소화한다.
- ControlNet 일반화: InfuseNet은 ControlNet 개념을 확장해, 텍스트 외에도 identity 및 선택적 컨트롤 이미지를 동시에 수용할 수 있는 multi-modality 주입 구조를 갖춘다.
- Plug-and-Play 호환성: 베이스 DiT 모델을 동결(frozen)한 상태로 유지하며 InfuseNet만 학습하기 때문에, Stable Diffusion 3.5나 FLUX 같은 다양한 DiT 기반 모델에 손쉽게 통합할 수 있다.
Multi-Stage Training Strategy

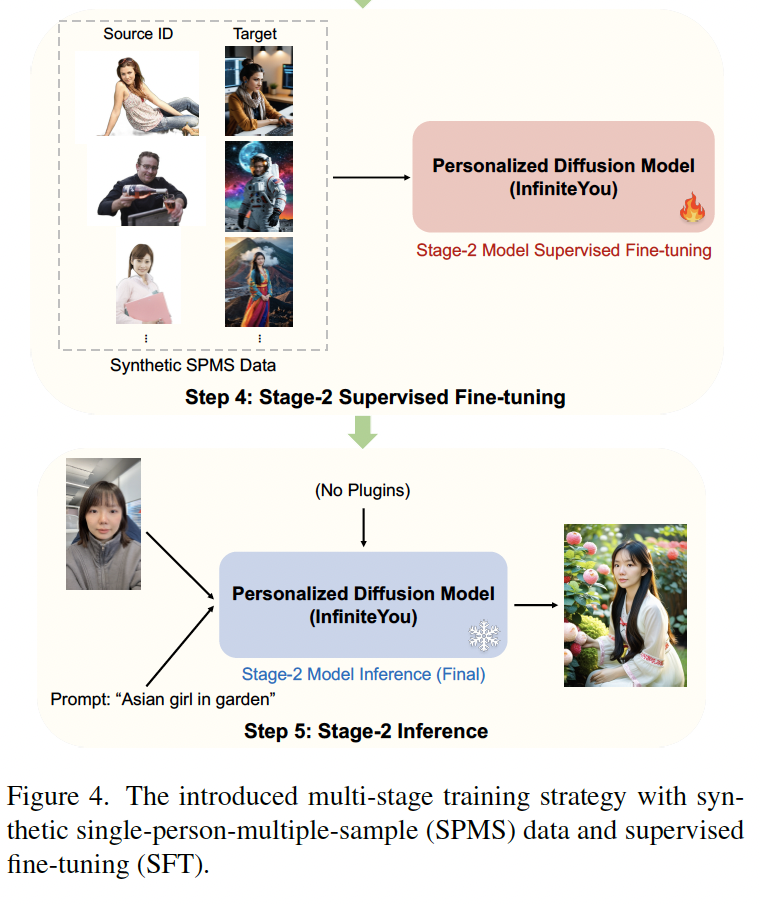
이와 같은 과정으로 진행된다고 생각하면 되고, 아래와 같은 세부적인 과정을 통해 이루어진다.
단계 1: 실제 인물 SPSS 데이터로 사전 학습
첫 번째 단계에서는 SPSS(Single-Person-Single-Sample) 데이터셋을 구축한다. 여러 인물 초상화 데이터셋에서 한 사람당 단 한 장의 사진만 추려낸 뒤, 그 사진을 identity input과 generation target으로 동시에 사용해 모델이 ‘재구성(reconstruction)’을 학습하도록 한다. 이 과정에서 모델은 얼굴의 주요 특징(눈·코·입·윤곽 등)을 어떻게 유지해야 하는지 기본기를 다지게 된다.
단계 2: 사전 학습 모델 초기 평가
SPSS로 사전 학습된 모델을 플러그인 없이 바로 Inference해보면 다음과 같은 결과가 관찰된다.
- 아이덴티티 유사도: 기대 이상으로 높음
- 텍스트–이미지 정렬: 아직 약간 어긋남
- 이미지 품질·미학: 전반적으로 밋밋하거나 노이즈가 남음
이 평가를 통해, 사전 학습만으로는 텍스트 지시에 따른 세밀한 조정이나 미학적 완성도를 모두 잡아내기 어렵다는 사실을 확인한다.
단계 3: SPMS 합성 데이터 생성
성능 격차를 줄이기 위해 Stage-1 모델에 Off-the-shelf 모듈을 연결해 고품질 합성 이미지를 대량으로 만든다.
- SPMS(Single-Person-Multiple-Sample) 포맷
- Identity Input: 실제 사진
- Target: 미적 보정 LoRA, 얼굴 스왑, 후처리 도구 등을 거친 다양한 합성 샘플
- 특징: 높은 해상도, 세련된 조명·색감·구도 갖춤
이 단계에서 확보한 합성 데이터는 ‘미학 학습용 교과서’처럼 역할한다. 하지만 이 과정은 시간이 조금은 오래 걸린다는 단점이 존재한다.
단계 4: SPMS로 지도 학습(Fine-Tuning)
합성 데이터를 이용해 Stage-2 Supervised Fine-Tuning을 진행한다.
- 입력: 실제 얼굴 → 출력: 고품질 합성 이미지
- 학습 목표
- 텍스트 지시대로 이미지를 정확히 조율하는 능력 강화
- 합성 데이터의 우수한 미학·화질 흡수
- 아이덴티티 보존 능력 유지
- 결과: SPSS 단계에서 부족했던 부분이 대거 보완된다. 특히 아이덴티티 보존 능력보다는 미학적 완성도가 완성되는 과정이라고 생각하면 좋다.
이때 기존 사전 학습과 거의 동일한 설정(러닝레이트, 배치사이즈 등)을 유지하면서, 단지 데이터만 SPSS에서 SPMS로 교체해 학습한다.
이러한 과정을 통해 학습을 진행함으로써, 아이덴티티 유사도와 asthetic한 완성도 2가지를 모두 챙길 수 있게 되었다.
Results / Ablation Study

기존 방식들과 비교했을 때에는 확실히 나은 결과임에는 틀림이 없었다. 이는 아마 controlnet을 통해서 추출했기 때문이 아닐까 생각이 드는데, 여기서 말하는 pickscore이라고 하는 것은 이제 여러 사람들을 불러놓고 평가를 맡겨서 점수를 산출한 것이라고 한다. 그래서 뭔가 다른 평가 지표에 비해서 신빙성이 덜한 느낌이 있는데, 그래도 뭐... 제일 좋다니깐....
오른쪽 테이블은 Ablation Study 란으로, 이제 여러 방법을 InfiniteYou에 적용해보면서 결과를 비교한 테이블이라고 볼 수 있다. 본 테이블을 보면 알 수 있듯이, 하나하나가 나을 수는 있지만 결국은 모두 합쳐졌을 때 가장 좋은 결과를 낼 수 있다는 것이었다. 아무래도 SPMS의 단점을 보완하기 위해 다른 방법들을 보완하고, 이렇게 하나하나 상호 보완적으로 사용한 것이기 때문에 그런 것이 아닐까 싶다.
Conclusion
결과적으로 이 모델은 성공저긍로 image recrafting을 해낸 모델이라고 할 수 있다. 하지만 이에 대해서 문제점을 제기할 수 있게 되었는데, 이러한 infuseNet 구조로 인해서 생길 수 있는 unsafe outcome의 문제들을 해결할 수 없다는 것이 가장 큰 문제점으로 제기되었다. 이러한 conclusion은 내가 이 논문을 읽은 이유기도 했다. 현재 concept erasure와 safe content generation에 대해서 연구를 진행하고 있기에, 이에 대해서 조금 더 고민해봐야겠다는 생각을 하게 되었다.
'Paper Review > Computer Vision' 카테고리의 다른 글
| [논문리뷰] AffordanceLLM : Grounding Affordance from Vision Language Models (3) | 2025.04.30 |
|---|
