
DeepSeek에서 또 새로운 사고를 쳤다. 기존 deepseek-v3만 해도 충분히 파라미터 대비 성능이 잘 나온다고 해서 말이 상당히 많은 상태였는데, 이제는 더 작은 파라미터로 o1과 거의 비슷하거나 그 이상의 성능을 내버리는 모델이 나오고 말았다. 일단 논문을 보고 올거라면 아래의 논문을 보기를 바란다.
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
We introduce our first-generation reasoning models, DeepSeek-R1-Zero and DeepSeek-R1. DeepSeek-R1-Zero, a model trained via large-scale reinforcement learning (RL) without supervised fine-tuning (SFT) as a preliminary step, demonstrates remarkable reasonin
arxiv.org
Abstract
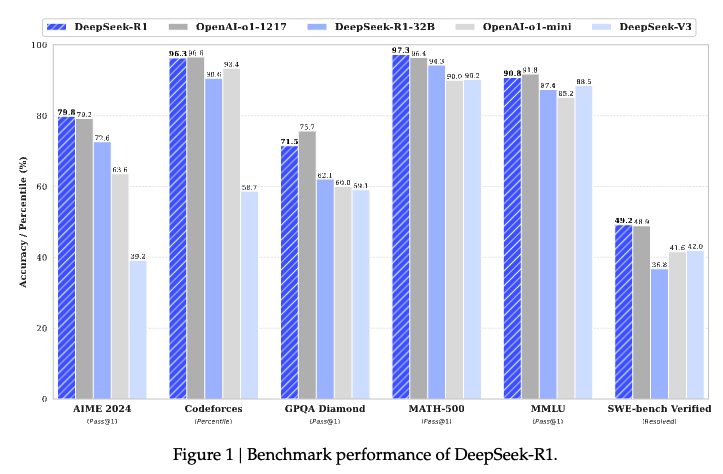
이번에 deepseek에서 내놓은 모델은 2개로, deepseek-r1-zero, deepseek-r1 2가지이다. deepseek-r1-zero는 Supervised Fine-Tuning(이후 SFT로 통일)가 없이 단순히 대규모 강화 학습(Reinforcement Learning, 이후 RL로 통일)만을 통해서 학습된 모델이었다. 이 모델 또한 충분한 reasoning behavior를 보였지만, readability / language mixing에서의 문제가 발생(SFT의 부재로 인한 문제점 발생). 이를 해결하기 위해 Multi-stage training, cold-start data를 RL 이전에 사용한 모델인 DeepSeek-R1을 제안한다. 아래와 같이 o1 닦아버리는 모습을 보이는데, 파라미터 수가 적다는게 정말 놀라울 따름임.
Introduction
지금의 LLM들은 점점 AGI(범인공지능)에 가까워져 가고 있고, o1같은 경우에는 Chain-of-Thought 기법을 활용해 성능을 올린 것을 알 수 있음. 하지만 test-time scaling(-> 추론 성능에 대한 확장)이 아직 해결되지 않고 있다. 여러 논문들에서 뺑이치면서 만들어놨지만, 아직 o1한테 다 닦이고 있는 상황이다.
그래서 deepseek-R1-zero 에서는 이를 pure RL을 이용하여 해결하고자 하였음. supervised Data 없이 self evolution으로 해결하고자 한 것. 아니 이게 말이 되나? -> deepseek Math팀에서 만든 방식인 GRPO(Group Robust Preference Optimization, 사용자 그룹의 선호도를 고려한 더 견고한 성능을 가지기 위한 강화학습 방식. 이후 추가할 예정)을 사용하여 o1의 perforrmance에 도달할 수 있었다 한다.

근데 앞에서 말했듯 poor readability, Language Mixing 등의 문제가 발생해서 이를 해결하기 위해 여러 방식을 사용하였다.
- cold-start data 사용 : base model인 DeepSeek-V3를 Fine Tuning을 하고 시작을 하게 된다.
- DeepSeek-R1-zero와 똑같이 GRPO 기반의 학습 과정을 수행한다.
- SFT를 도입 - rejection sampling, deepseek-V3의 QA, Self-Cognition Data 사용
>>> 이게 일종의 CoT 과정인 것이라 생각해도 될 듯함
https://arxiv.org/abs/2412.19437 <<< 논문 링크 참고(DeepSeek-V3임) - 이를 통해서 OpenAI o1-1912와 동등한 성능을 얻었다.

이게 왜 되나 싶긴 하지만, 이건 아마 아직 내 이해가 부족하기 때문 아닐까? 사실 유튜브를 뒤져봐도 일단 다 말이 안되니 돌려나 보자 이런 느낌으로 설명이 되고 있다. 실제로 외국에서는 이걸 똑같이 돌려서 성공하기도 했고, 애초에 지금 이 논문 쓴 DeepSeek가 중국기업이라 H100 수출제한이 걸려서 H800 2048개 가지고 돌렸다는 소문이 있어 더 대단해보이긴 한다. 일단 마저 보자.
일단 위에처럼 DeepSeek-R1이라는 모델을 만들어 냈고, 여기서는 또 다른 시도를 진행을 한다. 바로 Distillation을 활용한 것인데, 이거는 이제 모델을 더 경량화시킬 수 있는가에 대한 문제를 실험해보기 위함이라고 할 수 있다. 이렇게 진행이 되었을 때에도 위에 그래프의 DeepSeek-R1-32B와 OpenAI-o1-mini 2개를 비교해보면, 경량화된 모델 또한 o1-mini와 비슷한 성능을 보임을 알 수 있다. 이로써 일단 R1이 이제 단순 뽀록으로 만들어진 모델이 아니라, 정말 옳은 방법을 통해 옳게 만들어졌다는 어느 정도의 반증이 된 셈이라 생각이 든다.
DeepSeek-R1 Training Methods
이쯤되니 조금 궁금해지기 시작한다. 정말 어떻게 한걸까.... 한번 하나씩 알아보도록 하자.
- Cold Start
이는 위에서도 언급했듯, DeepSeek-R1-Zero의 초기 학습이 매우 불안정하고 결과에서 Readability가 낮고 Language Mixing이 발생한다는 문제점을 해결하기 위한 방식이다.
여기서는 CoT 데이터를 사용해 먼저 fine-tuning을 진행한다고 보면 된다. - Reasoning-Oriented RL
Cold start Data로 Fine-Tuning을 진행하고 나서, RL을 진행한다. 이는 이제 모델의 reasoning 성능, 특히 수학이나 논리, 코딩 등 명확한 해결책을 가지고 있는 reasoning-intensive tasks에서의 성능을 향상시키기 위함이다. 또한, 위에서 말했던 기존 문제점인 Language Mixing 문제점을 해결하기 위해 언어에 대한 일관성 보상을 추가했다고 한다. 이게 RL로 되다니,,, 아무리 봐도 기초가 중요하다는 생각이 든다. - Rejection Sampling + SFT
RL을 거쳐 나온 Checkpoint를 기준으로 해서 Rejection Sampling을 적용 -> 추론 데이터를 생성한다.
비추론 데이터(단순한 작문, 번역 등)은 베이스 모델인 DeepSeek-V3 데이터를 활용하였다. - RL(for Generalilzation)
모델의 유용성, 무해성(harmlessness)를 위한 RL 단계를 추가로 구현한다. 아마 천안문같은 예시를 막기 위함 아니었을까..

어느정도는 잘 막은 것 같지만, 이런게 눈가리고 아웅 아닐까 싶은 생각은 든다. 그래도 인정할건 인정해야지 이사람들아...
아무튼 위와 같은 단계를 통해서 기존의 Chain-of-Thought 방식을 RL 방식으로 대체할 수 있는 방안을 찾아내었다는 점에서 의의가 있다고 생각한다. 랩실 선배가 조만간 RL이 정말 대세가 될 것 같다고 얘기한지 한달밖에 안지났는데 참 세상 빠르다는 생각이 들고 있다.
Limitations
위와 같이 RL을 통해서 model의 reasoning ability를 늘리는 시도를 하는 것은 정말 좋다고 생각한다. 하지만 논문에서도 말이 나와 있듯, 이는 단순히 reasoning에 대한 ability이기 때문에 위의 benchmark에서는 좋은 성능을 겪게 되었지만서도 아래와 같은 문제점을 가지게 되었다.
- Function Calling, Role-Playing 등의 task에서는 기존 모델보다 떨어지는 모습을 보임.
- Language Mixing이 여전히 발생 : 학습을 중국어, 영어 기준으로 진행해서 발생한 문제인듯
- Few-Shot Prompting을 진행했을 때, 성능이 기존만큼 나오지 않는다고 한다.
뭐 이는 이제 DeepSeek에서 또다시 해결하고 있겠다 싶으면서도, 새삼 새로운 방법을 이와 같이 찾아낸 deepseek가 신기할 따름이다. 이 코드는 오픈소스로 심지어 공개가 되어 있으니, 한번쯤 사용해보는 것도 재미있을 것 같다.
'Paper Review > LLM' 카테고리의 다른 글
| [논문리뷰] EXAONE Deep: Reasoning Enhanced Language Models (0) | 2025.03.18 |
|---|---|
| [논문 리뷰] AoT : Atom of Thoughts for Markov LLM Test-Time Scaling (0) | 2025.03.11 |

